
As machine learning models grow in complexity, deploying them in real-world environments—especially on resource-constrained devices—requires a shift from “bigger is better” to “smaller and smarter.” One powerful method to achieve this is model pruning.
Pruning is a technique that removes less important parts of a neural network (such as weights or neurons), reducing the overall size and computational cost of the model. This process leads to more efficient models that can run faster and require fewer resources, often with little or no drop in predictive performance.
The following two pruning techniques are applied to reduce model complexity and improve efficiency:
Unstructured pruning removes individual weights from the network based on their importance. This type of pruning leads to sparse weight matrices and can significantly reduce parameter count.
Structured pruning removes entire neurons, channels, or attention heads, resulting in a physically smaller model with fewer operations (FLOPs). This is especially beneficial for hardware acceleration.
In practice, combining unstructured and structured pruning provides a balanced trade-off:
In the context of the SEDIMARK project, which focuses on secure, efficient, and decentralized AI workflows, pruning plays a vital role in optimizing model deployment across diverse and potentially resource-limited environments. By reducing model size and computational load, pruning enables faster inference and lower energy consumption — both critical for real-world deployment on edge devices and within federated learning systems integral to SEDIMARK's architecture.
In our internal experiments, applying pruning to transformer-based time series models demonstrated clear benefits:
Different pruning strategies showed strengths in different areas:
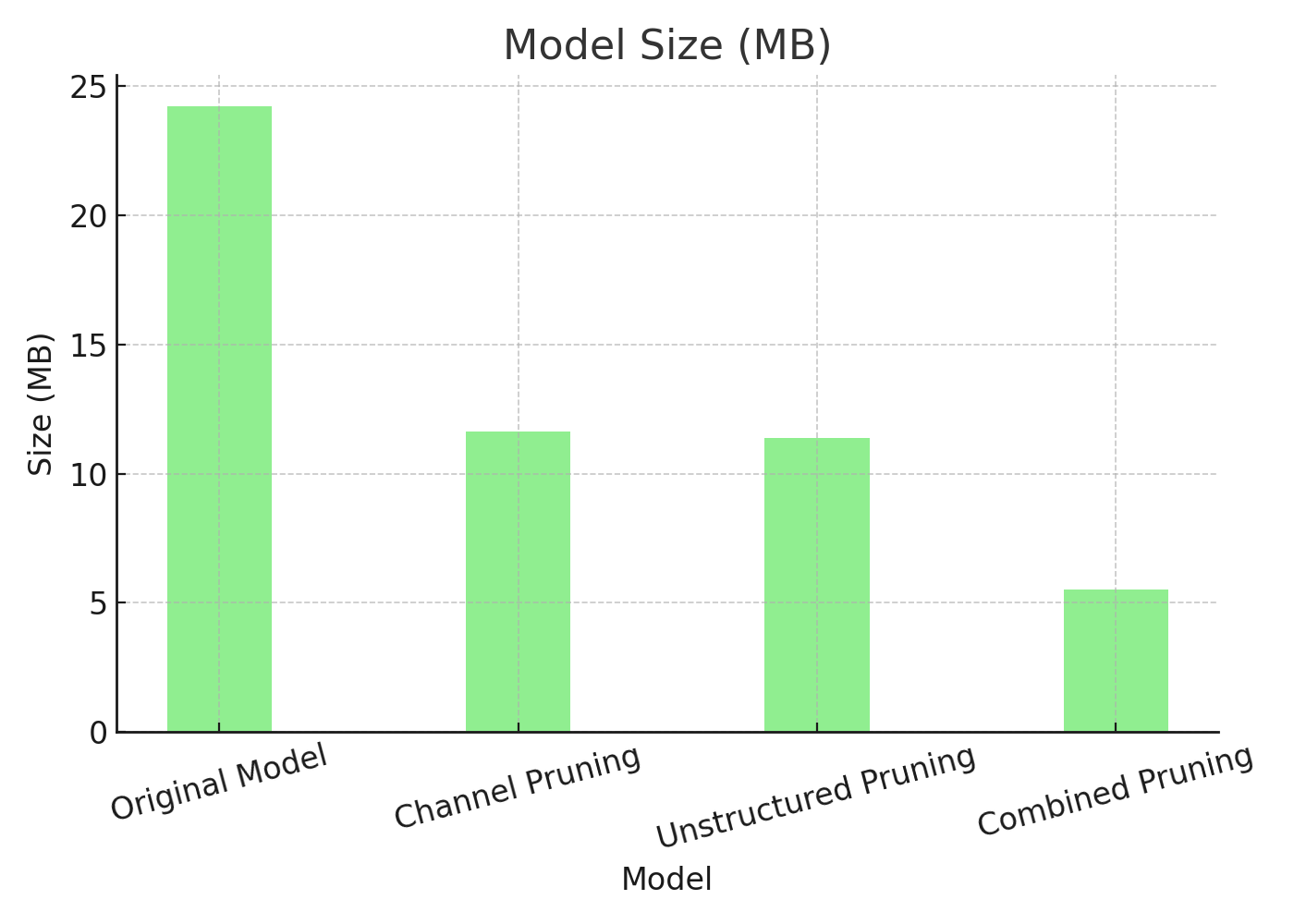
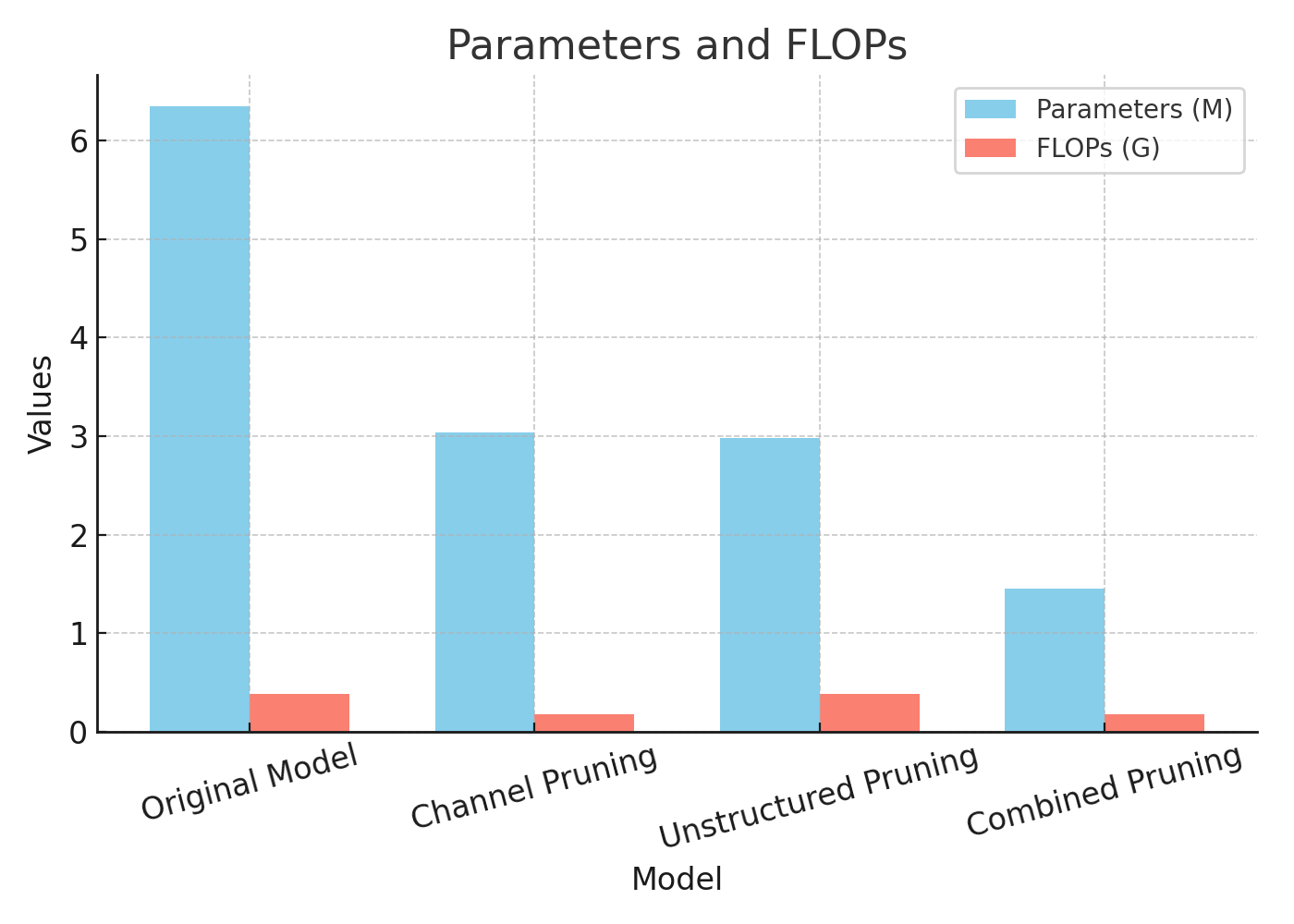
You can refer to the graph above for a visual representation of the benchmarking results.
This software has been developed by the University of Surrey under the SEDIMARK(SEcure Decentralised Intelligent Data MARKetplace) project. SEDIMARK is funded by the European Union under the Horizon Europe framework programme [grant no. 101070074]. This project is also partly funded by UK Research and Innovation (UKRI) under the UK government’s Horizon Europe funding guarantee [grant no. 10043699].