This week, SEDIMARK participated in the workshop on ‘Tech Adoption Scenarios and Data AI 2030’ that was organised by the LeADS project (Leading Europe’s Advanced Digital Skills), which is a Coordination and Support Action (CSA) funded by the Digital Europe Programme, and among other objectives, it aims to provide guidance for the deployment of the DIGITAL programme Advanced Digital Skills (ADS) over the next 7 years.
The aim of the workshop was to assess the key predictions developed by LeADS for market adoption within the AI and Data technology areas which included over 80 tech groupings.
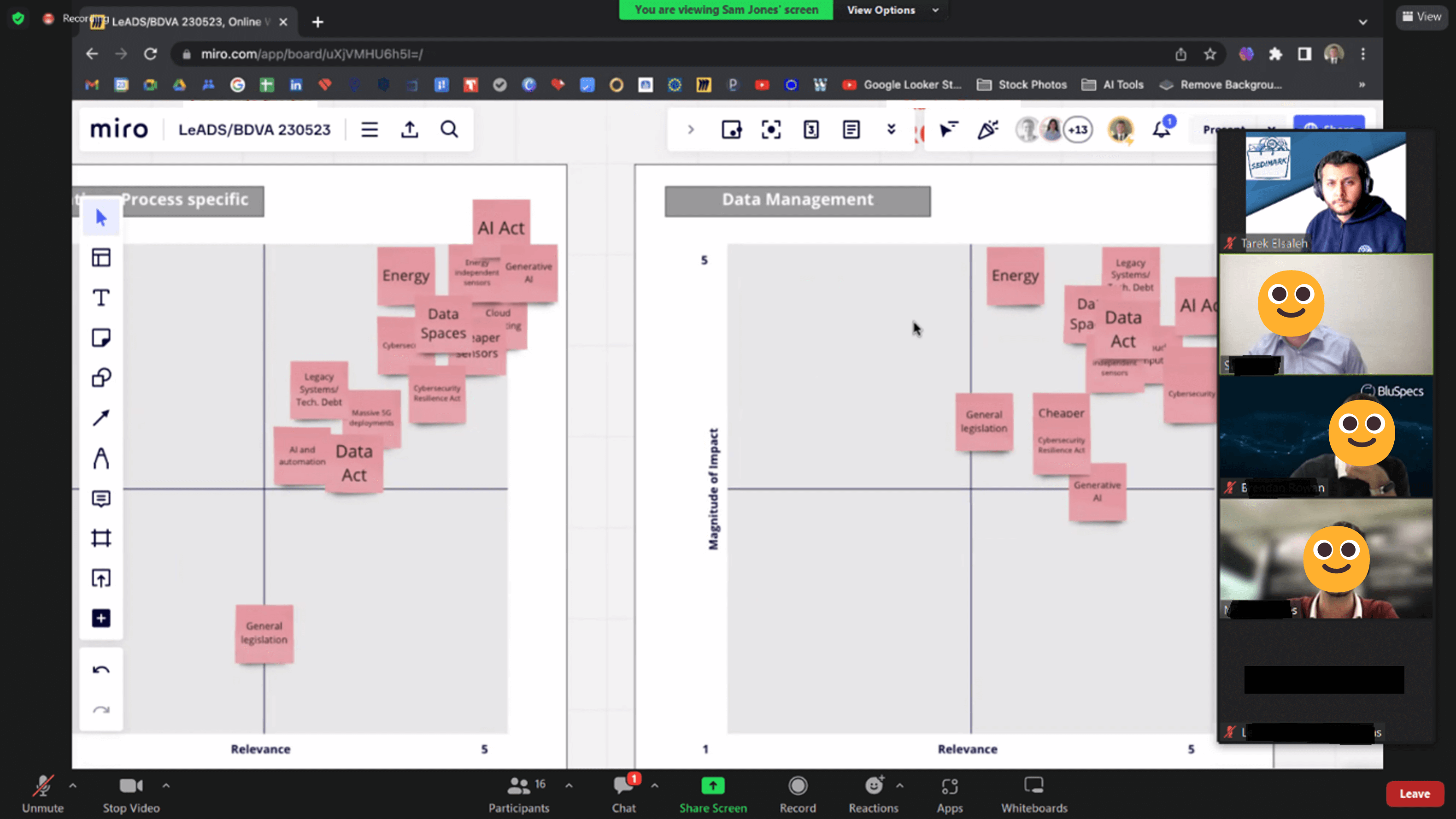
From SEDIMARK, University of Surrey (@cvssp_research) contributed to the co-creation exercise facilitated by Martin Robles from BluSpecs, which focused on the definitions of market dynamics in relation to data management and analysis.
The exercise involved assessing:
Most of the use cases listed were applicable since data management plays a central role in most technologies, which include remote health monitoring, environmental monitoring detection, manufacturing operations and agricultural field monitoring.
In relation to legislation, compliance oversight over different aspects of data management will be expected to increase, and a possible impact of this is that there will be significant reservation among developers to provide decentralised and distributed solutions to address today’s massive energy consumption of cloud-based centralised systems, by handling data closer to the data source, which in many scenarios will require collaborative data sharing between different data providers. And this will inevitably raise alarms regarding data protection, and therefore compliance entities need to cooperate and clarify, rather than police tomorrow’s developers.
With regards to AI automation, the hypothesis presented was that more automation of digital systems will be driven by AI throughout an application’s development lifecycle. This would be the case for well-established uniform processes, but not yet for processes dealing with new or unfamiliar data sources especially when it comes to handling semantic interoperability.
As for Cybersecurity, an increase in experts in this field is expected due to the increase in federation of data flows and models in systems. This will highly likely be the case as there will be a need for auditing mechanisms for checking data integrity and provenance to ensure the correct use of data and AI models.
Finally, when it came to assessing the relevance and magnitude of the impact of data management on today’s main technology, most areas listed were expected to be highly affected by how skills in data management will evolve.
In conclusion, the workshop highlighted possible scenarios on how skills development in the future will be influenced, especially when it comes to balancing innovation in data management and the protection of data.