In the dynamic City of technological progress, Lidar sensors, or Light Detection and Ranging sensors, have emerged as pivotal tools in the development of smart cities. These sophisticated sensors utilize laser light to gauge distances and construct intricate three-dimensional maps, providing a trove of data that is reshaping urban planning, traffic management, and public safety on a global scale.
Among the many applications of Lidar sensors in smart cities, their integration into autonomous vehicles stands out as particularly impactful. Self-driving cars heavily rely on Lidar technology to navigate their surroundings with precision and safety. By emitting laser pulses and measuring the time it takes for the light to return, Lidar sensors generate real-time data crucial for autonomous vehicles to navigate obstacles, maintain safe distances, and adhere to traffic regulations. As cities worldwide embrace autonomous vehicles in their public transportation systems, Lidar technology is poised to play a pivotal role in ensuring the safety and efficiency of these fleets.
In a notable example, the Helsinki pilot, in collaboration with the companies, has implemented Lidar sensors in its city center, specifically in the Esplanadi streets and pathways. Three Lidar radars have been strategically placed to collect data on moving vehicles, bicycles, electric scooters, and pedestrians. This real-time information is gathered and analyzed with utmost respect for privacy. The Lidar data analysis in this initiative aims to explore the potential of extracting detailed information about movement patterns in the area. This data, derived from advanced Lidar sensors, could be instrumental in enhancing the safety and appeal of the region.
The Lidar sensors strategically placed in the area combine their data to generate precise representations of factors such as traffic flow, potential hazards, and the volume of pedestrians and light traffic. These sensors create detailed three-dimensional models of the environment, offering a comprehensive understanding of how different factors, including seasons, events, and traffic arrangements, influence pedestrian and light traffic patterns.
The data collected through Lidar sensors not only aids in understanding current scenarios but also opens doors for future improvements. The Helsinki project aims to explore whether analyzing this data can enhance the safety of commuters, improve cycling efficiency, and boost the overall attractiveness of the area for pedestrians. Importantly, the project focuses on anonymous behavior analysis rather than individual tracking, respecting privacy concerns.
The recently concluded ecosystem workshops at Helsinki Mobility Lab have provided invaluable insights into the world of digital twins and data marketplaces. In particular, discussions surrounding the Mobility Data Marketplace have shed light on crucial aspects that will shape the future of this evolving landscape.
Maintaining a strategic focus at the conceptual level has proven instrumental in comprehending the dynamics of mobility data marketplaces. By centering discussions on needs and concerns, we move beyond mere technical solutions to delve into fundamental questions regarding data acquisition, sharing, and utilization in the realm of mobility. This is the space where the mobility digital twin demonstrates its value, revealing new opportunities for urban city development.
In the context of value creation and processes within the digital twins, data becomes a catalyst for process optimization. By leveraging information from other functions more broadly, we can gain a better understanding of our operations' role as part of the whole and anticipate future needs.
Trust emerges as a central theme, especially in a market focused on mobility data. Building mechanisms for trust from the ground up and sustaining it as the ecosystem expands is not only a recommendation but a necessity for the success of mobility data marketplaces.
The recommendation to initiate roadmap work and benchmark solutions from other industries is particularly relevant to the dynamic landscape of mobility. Learning from successful models in related fields can accelerate the development of effective mobility data marketplaces
Aligning with the workshop approach, incremental progress through pilots is crucial for the mobility data marketplace. The tangible actions resulting from such an approach validate decisions made during conceptual discussions, ensuring that the marketplace evolves in a way that best serves the needs of its participants. Constructing a roadmap for a data marketplace specific to mobility requires a nuanced understanding of the unique challenges and opportunities within this sector.
As we delve deeper into the complexity of the Mobility Data Marketplace, it becomes evident that the roadmap to a successful mobility data marketplace involves a combination of strategic discussions, practical considerations, trust-building measures, and iterative progress. The future roadmap positions us well for the challenges and opportunities that lie ahead, steering us towards a future where the effective utilization of mobility data contributes significantly to innovation and sustainable development.
Mobility Lab - Digital Twin, Data Marketplace workshop
Micro mobility has emerged as a key factor in urban transportation systems, providing flexible and sustainable alternatives for short-distance travel. Electric scooters, bikes, and other zero-emission vehicles not only complement traditional modes of transportation but also reshape urban mobility, creating a more seamless and intelligent way of getting around.
Micro mobility offers urban dwellers a convenient way to navigate the hustle and bustle of the city, especially for short-distance trips. Electric scooters and bikes are quick and user-friendly, facilitating effortless transitions from one point to another. This makes them an ideal solution for addressing the last-mile challenge, transforming the journey from public transportation to the final destination into a smooth experience.
The congested areas of urban centers often pose challenges for transportation, but micro mobility provides a solution where vehicles can move quickly and flexibly through traffic, bypassing congestion and efficiently reaching their destinations. This speed and flexibility make micro mobility an invaluable part of urban transportation.
Helsinki is a pioneer in discovering and implementing new technological solutions and actively shaping the future of urban transportation, considering micro mobility and its integration into the city's transportation systems. Mobility Lab Helsinki is playing a crucial role helping companies with real users in this evolution by testing an AI and computer vision solution in traditional sensing and drones for analyzing transport modes and identifying infrastructure elements understanding micro mobility within urban environments and Digital Twin. The use of artificial intelligence and computer vision enables contributing to the development of safer and more seamless transportation solutions.
Micro mobility is not only convenient but also an environmentally friendly option. Electrically powered vehicles reduce transportation emissions, promoting sustainable urban transportation. Smaller carbon footprints make micro mobility an attractive choice for those who want to positively impact the environment.
Evolving technologies, such as smart sensors and AI, offer more opportunities to enhance the usability and safety of these zero-emission vehicles. Collaboration with traditional transportation systems can create a harmonious urban environment where different modes of transportation work seamlessly together. The broad adoption of micro mobility in cities, combined with new initiatives indicates that the future of mobility is diverse, intelligent, and continually evolving. Zero-emission vehicles are not just a trend; they play a crucial role in the development of urban transportation towards a more seamless and sustainable future.
Decentralized data spaces that facilitate real-time data sharing among ecosystem operators and mobility providers are essential in addressing the complex challenges of urban mobility and data sharing. These data spaces provide a foundation for innovation, efficiency, sustainability, and safe and efficient information gathering. The SEDIMARK use case pilot explores the mobility digital twin concept to lay the groundwork for future building blocks in secure decentralized mobility data spaces in urban environments.
As inferred by the project acronym itself, SEDIMARK is a data-driven project, joining the global trend where individuals and companies produce tons of data on a daily basis.
The initial impulse in any initiative of this type involves focusing on the purely operational and organizational aspect. However, if we stop to think about the treatment carried out on these generated and collected data, the imperative need to dedicate space to the ethical section of its manipulation falls under its own weight.
Hence, the European Commission recommends for this kind of project to check periodically potential ethical issues. First, to make sure that the project does not use personal data (or if it happens to use that this is in compliance with GDPR and other relevant requirements) and second because this specific project will use AI-based solutions and thus it is important to make sure that they are in line with the standards in this area.
Attention to these ethical issues should not fall exclusively on the members of the consortium, who are ultimately interested parties in the process. That is why it is advisable to have opinions from voices external to the project, with proven experience in the project's work areas, capable of evaluating with a critical and well-trained eye the work carried out by SEDIMARK to preserve an ethical approach. These people make up the so called ethics board.
In the context of SEDIMARK, such Ethics Board will proactively support the development of the project, act as a knowledge and guidance forum, and provide advice to the consortium on how to exploit knowledge created by the project.
Hence, SEDIMARK partners will invite the Ethics Board members on a regular basis to discuss about ethical aspects taking into account the project evolution, keeping them well informed of all relevant publications and/or events SEDIMARK-related.
The purpose of every Ethics Board Member participation is to contribute to a series of objectives through the provision of assessment to the project consortium on topics such as:
For all of the above, Ethics Board members will act as advisors in order to follow ethical issues, based on the report that the consortium will prepare on a yearly basis. Such report specifically focuses on explaining data protection issues (if any) and compliance with AI ethical standards. Its initial iteration was already issued during the first year of the project execution and will be a subject for updates along the way.
#Ethics #AI #DataSharing

This deliverable is a first version of the deliverable named “Edge data processing and service certification”.
The work has focused on identifying the building blocks required to develop a framework for deploying AI-based data processing and sharing modules at edge data sources, considering edge-cloud interactions following MLOps principles. It involves analysing various ML frameworks such as TensorFlow, PyTorch, tinyML, and edgeML, while addressing security and privacy concerns by implementing adaptive edge anonymization or tagging of sensitive data.
At this stage of the project these topics are still quite exploratory; this report focuses thus more on challenges, considered options and possible implementation choices. The last version of this deliverable, which is due M34 (July 2025), will provide all the details about the technical choices and their implementation.
This document, along with all the public deliverables and documents produced by SEDIMARK, can be found in the Publications & Resources section.
SEDIMARK D3.3 “Enabling tools for data interoperability, distributed data storage and training distributed AI models” is a report produced by the SEDIMARK project. It aims at providing insights in relation to progress made for:
Data quality is considered to be of the highest importance for companies to improve their decision-making systems and the efficiency of their products. In this current data-driven era, it is important to understand the effect that “dirty” or low-quality data (i.e., data that is inaccurate, incomplete, inconsistent, or contains errors) can have on a business. Manual data cleaning is the common way to process data, accounting for more than 50% of the time of knowledge workers. SEDIMARK acknowledges the importance of data quality for both sharing and using/analysing data to extract knowledge and information for decision-making processes.
Common types of dirty or low-quality data include:
Thus, one of the main work items of SEDIMARK is to develop a usable data processing pipeline that assesses and improves the quality of data generated and shared by the SEDIMARK data providers.
This document, along with all the public deliverables and documents produced by SEDIMARK, can be found in the Publications & Resources section.
"Much as steam engines energised the Industrial Age, recommendation engines are the prime movers digitally driving 21st-century advice worldwide"
Recommender systems are the prime technology for improving business in the digital world. The list is endless, from movie recommendations on Netflix to video recommendations on YouTube, to playlist recommendations on Spotify, to best route recommendations in Google Maps.
Recommender systems are a subset of Artificial Tools designed to learn user preferences from the vast amount of data, including but not limited to user-item interactions, past user behaviours, and so on. They are capable of delivering individualised, tailor-made recommendations that enhance user experience while boosting business revenue.
In SEDIMARK our goal is not only to provide a secure data-sharing platform, but also to enhance the experience of our users through the use of Recommender Systems at multiple levels:
SEDIMARK is a platform offering a vast amounts of data available for purchase in a secure way. To enhance the user experience, the team at UCD is developing cutting-edge recommender systems specifically targeted at dataset recommendation. The system will leverage data from past users’ behaviour such as past purchases, past browsing history, or behaviour of other similar users.
Apart from datasets, SEDIMARK will also offer ready-made AI models capable of extracting information from the specific dataset, such as for example weather forecast AI model that can learn from weather data collected by sensors. The recommender system in this category will be able to suggest the most relevant AI models for the given dataset. This will allow the users to fully explore the potential of the purchased dataset within the SEDIMARK platform.
Depending on the size of the purchased dataset and the complexity of the AI model, SEDIMARK will also aim to suggest the appropriate computation services that can carry out the learning process and are available within the SEDIMARK platfrom.
Using a single platform, users in SEDIMARK will be able to perform data discovery, learn insights from a given dataset using AI models and utilise computational services.
In the strive to achieve interoperability in information models, it is important to relate concepts that we define in our models to others that have already been developed and have gained popularity. This can be done by reuse, inheritance or an explicit relationship with that concept. There are many approaches to ontology development, but by far, Protégé has been the de facto tool. Reusing concepts from another ontology in Protégé involves importing the relevant axioms from the source ontology into your current ontology. Here is a quick tutorial on how to achieve this:
Start Protege and open the ontology where you want to reuse concepts.
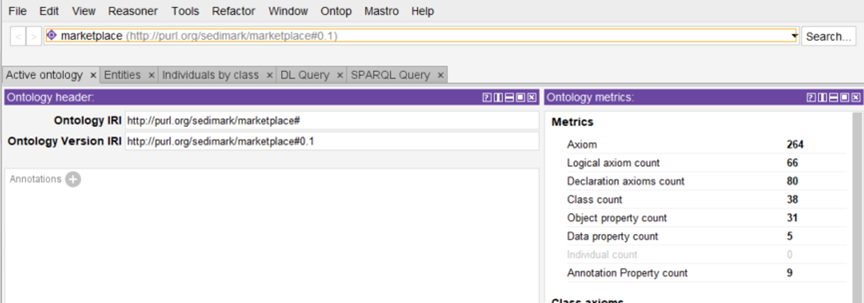
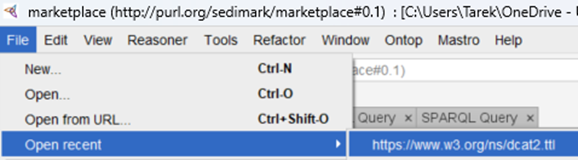
Protégé provides tools like ‘Refactor’ to copy or move axioms between ontologies.
You can select specific classes, properties, and axioms to import into your ontology.
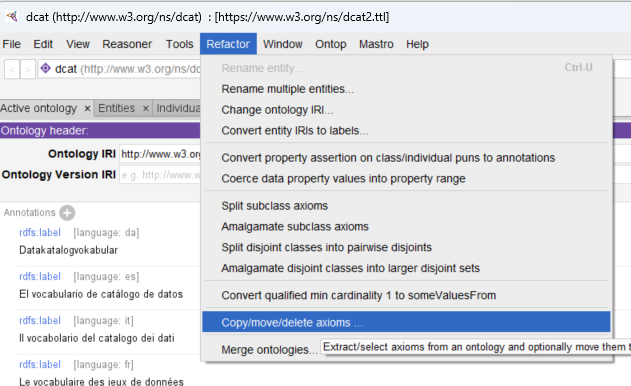
Select Axioms by reference, which will include other relationship with respect to the concept to be reused.
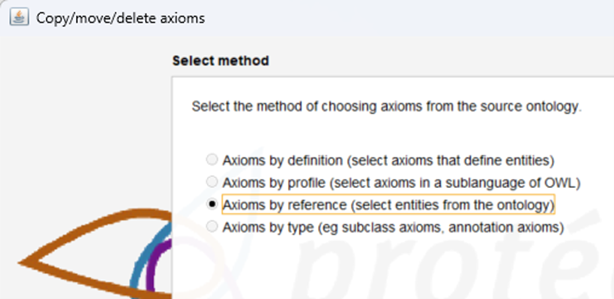
Select the concepts required:
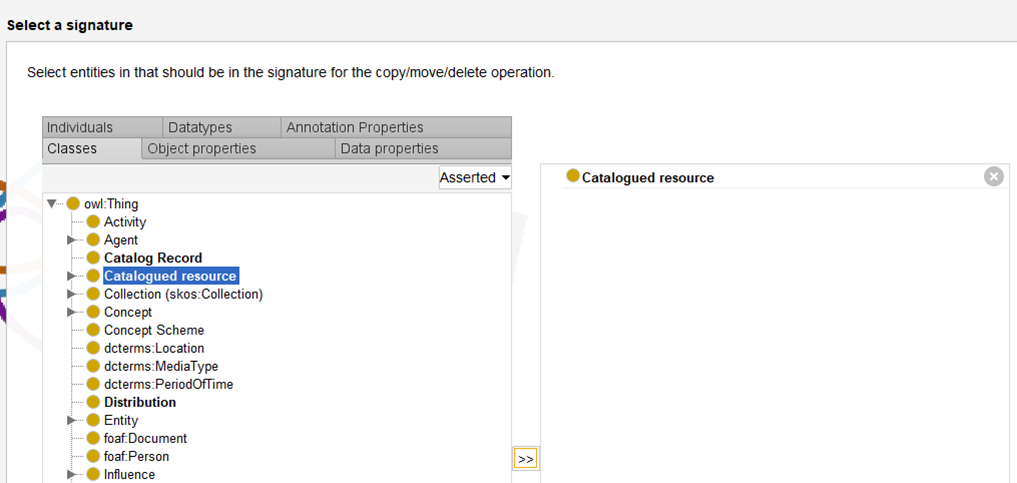
Check that the other axioms to be included are relevant.
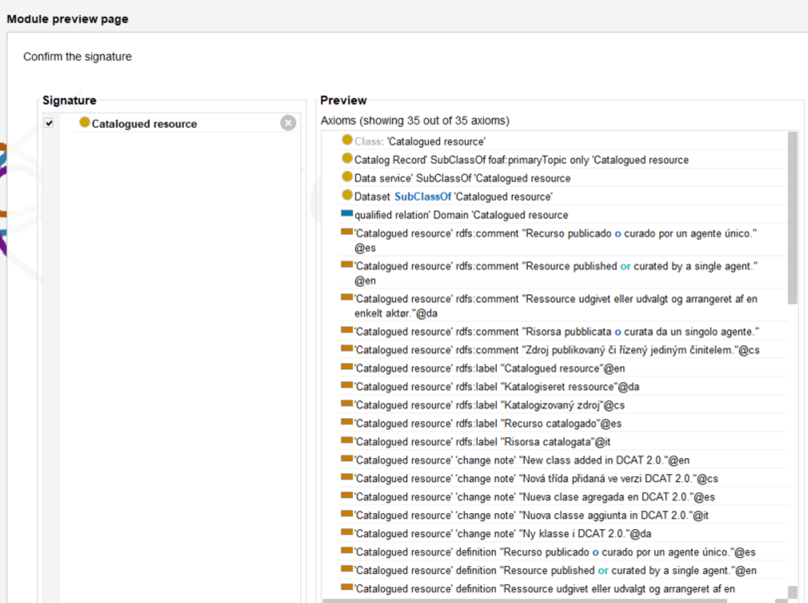
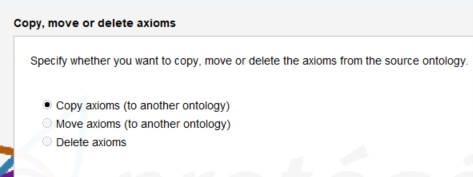
Select your ontology as the target.
Ensure that the namespaces for the reused concepts are correctly managed in your ontology to avoid conflicts.
After reusing the desired concepts, save your ontology to apply the changes.
To note, reusing axioms from another ontology may result in new logical consequences, therefore consistency and correctness of the developed ontology should be validated after the reuse process.
In response to the growing demand for secure and transparent data exchange, the infrastructure of SEDIMARK Marketplace leverages cutting-edge technologies to establish a resilient network.
This is the first version of the decentralised infrastructure and access management mechanisms. This deliverable presents a comprehensive overview of the decentralized infrastructure and access management mechanisms implemented in the SEDIMARK Marketplace. As the landscape of data exchange evolves, the decentralization approach ensures increased security, transparency, and user-centric control both over data assets and user identity information. Data providers of the SEDIMARK Marketplace can also provide additional types of assets, related to their data. Examples are Machine Learning (ML) Models, data processing pipelines and tools.
Operating within the principles of decentralization, this project addresses the growing need for secure and transparent data exchange in a globalized digital economy. The SEDIMARK Marketplace leverages distributed ledger technologies to establish a resilient and scalable infrastructure. The decentralized architecture of the marketplace is built on a robust distributed ledger employed for user identity management, as well as blockchain foundation, fostering tamper-resistant contracts. Utilizing a distributed network, the infrastructure eliminates single points of failure, enhancing reliability and ensuring the continued availability of assets to be exchanged. The decentralized infrastructure supports standardized protocols for data exchange, enabling collaboration and data sharing across various platforms and participants.
This deliverable is the first capstone in the SEDIMARK project, realizing the underlying infrastructure and mechanism that allow the fulfilment of the functionalities defined for the Marketplace. An updated version of this deliverable will be provided in the next Deliverable SEDIMARK_D4.2 in July 2025.
This document, along with all the public deliverables and documents produced by SEDIMARK, can be found in the Publications & Resources section.